The trigger bus
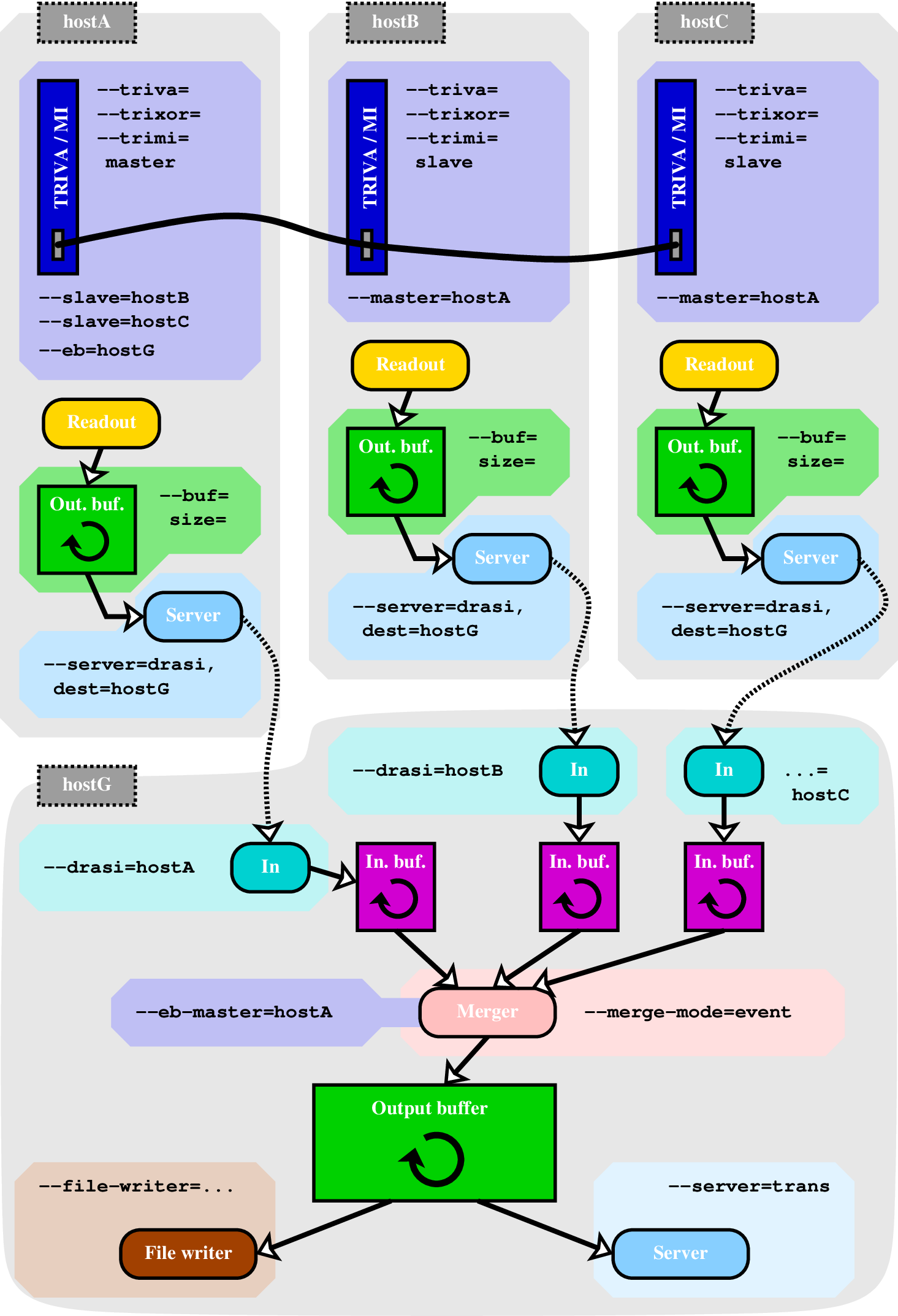
Multi-crate readout can be synchronised using a trigger bus between trigger modules. The data in both the readout nodes and the event builder is fed through circular data buffers. Options are used to configure both the trigger bus topology as well as the data flow.
GSI trigger module and bus
The trigger module together with the trigger bus ensures that it is virtually impossible to get mixed events at the event builder level, i.e. events where data from one system for one event is erroneously joined with data for another event from other systems. This is ensured by the trigger bus transmitting a 4-bit event counter for each event, which is compared to a local counter in each slave module. Any mismatch is immediately reported as a failure, requiring a re-initialisation. When the trigger bus has no electrical problems, mismatches never happen. (The author has seen it once - at that time a cable was likely stepped on.) The readout software also maintains a local counter which for each readout is checked versus the counter in the module, ensuring that also no trigger module fail to report a trigger to its readout process.
A mismatch would for example occur if the dead-time from a slave is not taken into account by the master, thereby allowing additional triggers that the slave cannot handle. Since the slave will ignore the trigger that comes during dead-time and not increment its local counter, the next event taken by the slave will mismatch. This occurs with the TRIMI trigger link when the dead-time return path has not been cabled.
Although the above is enough to detect and prevent event mixing, the use of (occasionally) different trigger numbers provides a second verification. Each trigger is associated with a trigger number 1-15 (where 12-15 are reserved for special use), which is sent from the master to each slave. While the slaves cannot verify that any trigger number is correct, the event-builder will check that all systems have matching trigger numbers for each event. In case of an inconsistency, a re-initialisation is necessary, to ensure synchronous operation.
The above checks are all very simple, mostly catered for by the trigger modules and bus, while the software side is very light. Two things follow from this:
Any mismatch, event counter failure or trigger number inconsistency is almost certainly due to a problem with the connections in the setup.
The rather complicated restart procedures described below have very little chance to affect the above checks, in particular to fail to detect faults. The verification in readout mode is not influenced by the data acquisition state machine (DASM).
Drasi wants to run
As soon as all systems (master, slave, and any event-builder) that make up one dead-time domain are present and can communicate with each other, drasi will test the trigger bus connectivity and if successful start the acquisition. If any issue happens, either during the start-up sequence or readout, the process starts all over. drasi never quits trying, unless obvious hardware faults within a node are detected. Note that a miscabled trigger link is between nodes, not within a node; attempts to start will go on until correctly cabled.
It is thus also perfectly fine to terminate the process of a drasi node, and restart it again. Usually, things are running within one or a few seconds again.
Start-up sequence in detail
The start-up orchestration and following basic monitoring during readout is conducted by the DASM of the master readout node. It follows the following sequence. If no slaves or event builders are present, the associated steps are skipped:
Wait until network connection with all configured slaves and event builder has been established.
Tell event builder that it can complete any previous consistent data, but then should wait for identification events.
Request master TRIVA/MI control/readout thread to set trigger module up, and inject an identification event (with random marker values given by the DASM).
The identification events will follow the normal data flow, and if an the event builder is connected, it will process data until this point and then hold. The identification events are an internal concept and only propagated by the internal drasi protocol, not to other network clients or data files.
Request all slave TRIVA/MI nodes to also set up, and inject identification events.
Validate all sources of the event builder.
The event builder will process and merge events as long as all sources have normal events with matching trigger numbers. As soon as one source fails this, due to mismatch or lost connection, all sources are expelled from the merging process and enter validation:
During validation, data is discarded until an identification event is seen. The DASM will tell the event builder whether it has the correct marker values to be a current identification event or not. If yes, then the source is made ready for merging. If no, validation of the source continues by discarding further data, looking for the next identification event.
This process ensures that all sources of an event builder are at the same location (and actually have no further data pending). It also ensures that all sources are nodes belonging to the same master trigger bus domain, since they are validated by the same master DASM. (It is however legal to omit some members of the trigger bus domain as sources from the event builder.)
If the event builder fails to receive identification events for some sources within a few seconds, the DASM will request new ones to be issued by systems that have not yet had their identifications verified. This handles the case of a network data connection having been recently established, without redoing the full restart procedure.
When this point is completed, the event-builder is ready to merge events, once it receives data.
Perform trigger bus / link connectivity test:
This procedure is based on the fact that software triggers take effect immediately after dt is released. (At least in TRIMI…)
Tell and wait for all slaves to enter test mode, which means to expect a trigger bus trigger.
Request the master to issue a test trigger, and wait for it having been issued.
Query all systems for reception of the (correct) trigger.
Request and wait for all systems except one to release dead-time.
Verify that dead-time is still present in the master system.
Release dead-time in last system.
Master has already issued the next trigger to be tested, or put the system in HALT mode, such that no experiment triggers are accepted yet.
The testing procedure will cause (spurious) start signals to be generated by the trigger module. This should be no problem, as the user readout code has not yet handled the start-of-run event (trigger 14), on which they anyhow have to set a clean state.
Tell and wait for all slaves to enter run mode.
Tell and wait for master to enter run mode. This means to issue a software trigger 14 and then handling triggers as usual.
Monitor the readout.
Once every second, the master is queried for the current event counter value and dead-time status. If the counter has not changed since last time, and the system was and is in dead-time, a lock-up situation is suspected. In that case, also all slaves are queried in order to find out if the long dead-time is due to a buffer full situation (which the user is simply warned about), or due to a mismatch, requiring a re-initialisation. (Slaves will upon detecting a mismatch actually immediately alert the master, which will do a quick status query). Before diagnosing the situation, the master is queried again to verify that the situation is still present before being reported.
Once every second any event builder is also queried. If the event builder has detected a mismatch, it will have expelled all sources from merging, and thus will make no further progress without re-initialisation. This regular check is to ensure that the situation is detected in a timely fashion, and not only after all intermediate buffers have filled up. (Like the slaves, also the event builder will alert the master to do a quick status query.)
Every eight seconds, the event counter of all slaves are checked. They should be within the range that the master had in its query before and after the slave queries. If not, then the slave is out of sync, and a restart is needed. (Most likely, the slave has lost its trigger connection). Also this check is to ensure detection in a timely fashion, without waiting for intermediate buffers of other readout nodes to have filled up.
If an error is detected in any of the steps above, the process is started over from the beginning.