Performance tests¶
The performance of a data acqusition system should be limited by the involved hardware, not software. Since drasi is not doing readout, but mainly organises network transfer, it should ideally have a very low impact.
As drasi can run with various hardware in different configurations, only some specific values for particular configurations can be given. It is notoriously difficult to repeatably measure performance at saturation, even more so with hardware. All measurements below are without any actual converter modules being read out. (This is not to be taken as any excuse for drasi to misbehave under real-world conditions, please report regressions.)
Readout node performance¶
The performance of the drasi code surrounding the user readout of each event has been tested with a RIO4 (r4l-11) sending data to an x86 event builder (x86l-80). A TRIMI logic was used as trigger module, and triggers were issued every 100 ns, giving almost 100% deadtime. No actual readout was performed, instead events of various lengths were faked, in order to vary the amount of work the network output thread had to do to send data to the event builder. The event builder hardware was fast enough to not be a bottle-neck.
The same hardware was also tested using MBS (v6.2) — the differences are negligible and of no practical importance. (In the first figure below drasi is marginally faster, in the next figure slightly slower.)
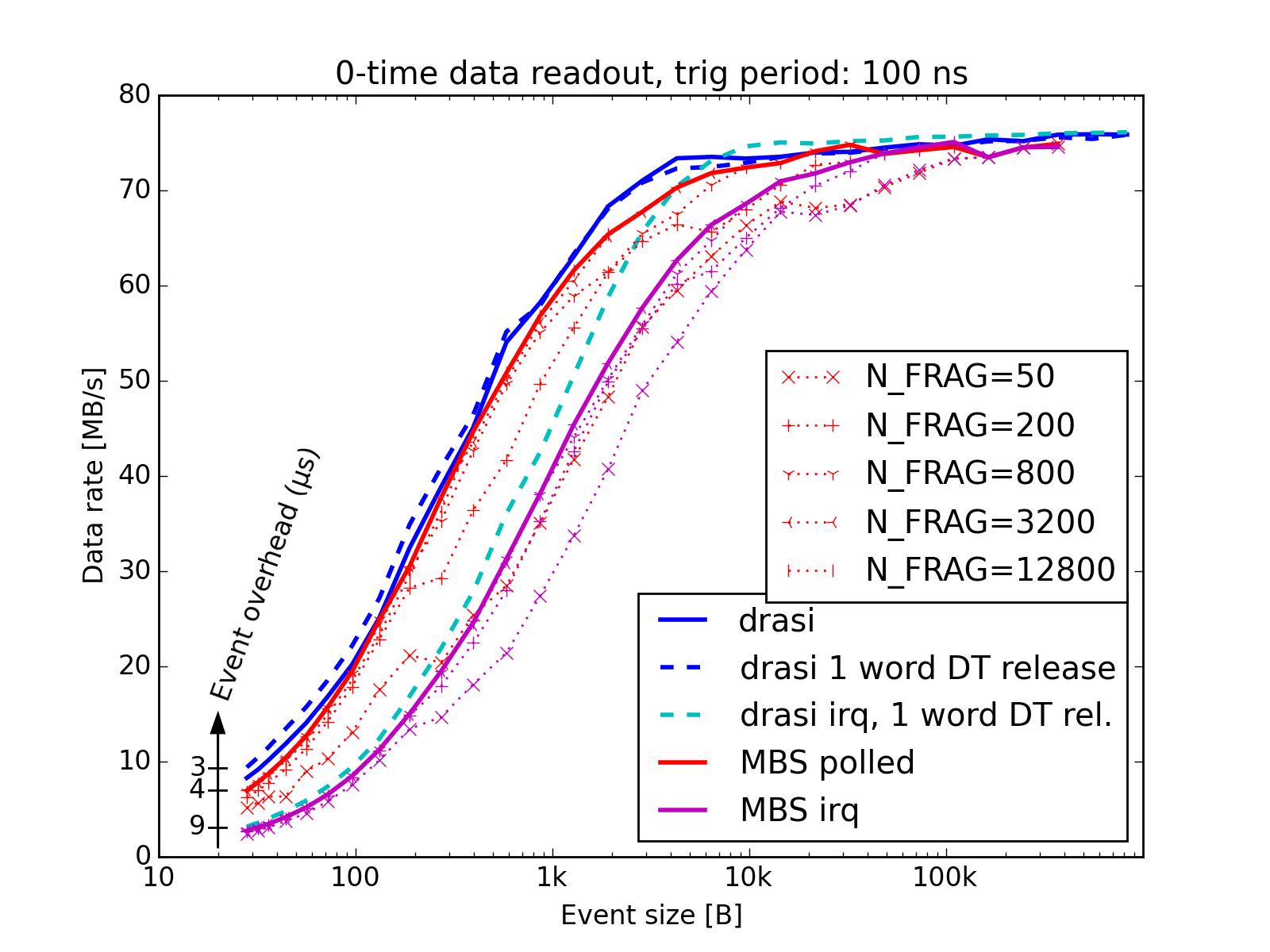
Readout performance of one RIO4 readout node sending data to an x86 event-builder, at highest possible event rate.
Notes:
- With large event sizes, the network output processing is the limit, for this RIO saturating at 75 MB/s. (This speed is reachable only since there is no actual readout).
- With small event sizes, the per-event overhead is the limit. The 3 us overhead corresponds to a 330 kHz empty event rate.
- Interrupted mode is less performant than polled mode.
- (To optimise MBS performance, the parameter
N_FRAGmust be tuned. MBS can also handle larger events than measured here, but continuous setup file editing is tedius.)
The same readout was tested under slightly more realistic conditions (not 100% deadtime), by issuing the next trigger randomly within a window of 0–20 us, averaging 6.6 us.
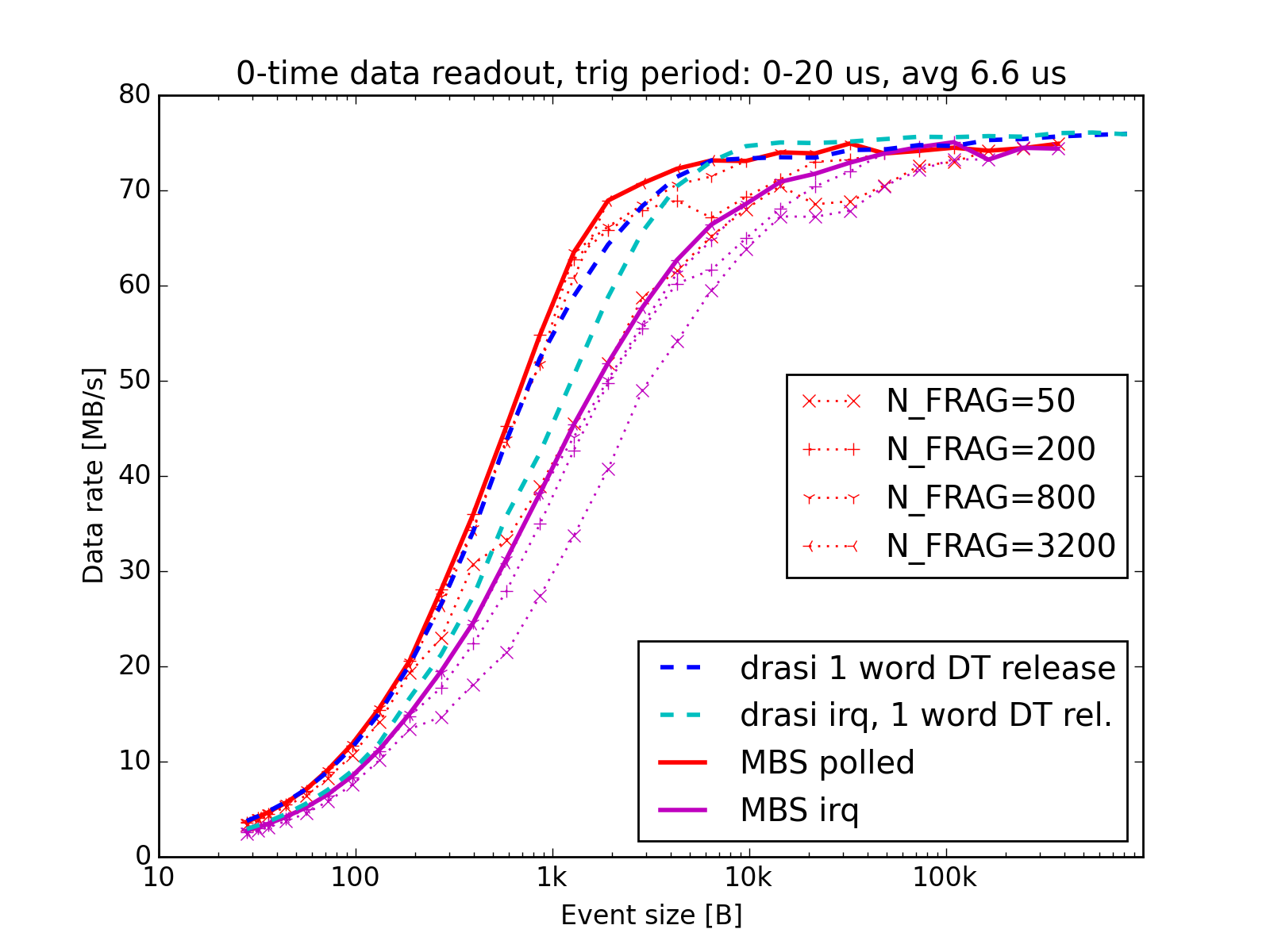
Readout performance of one RIO4 readout node sending data to an x86 event-builder, with 0–20 us livetime between events.
Merger performance¶
The performance of the event builder / time sorter stage has been tested on one 4-core workstation machine.
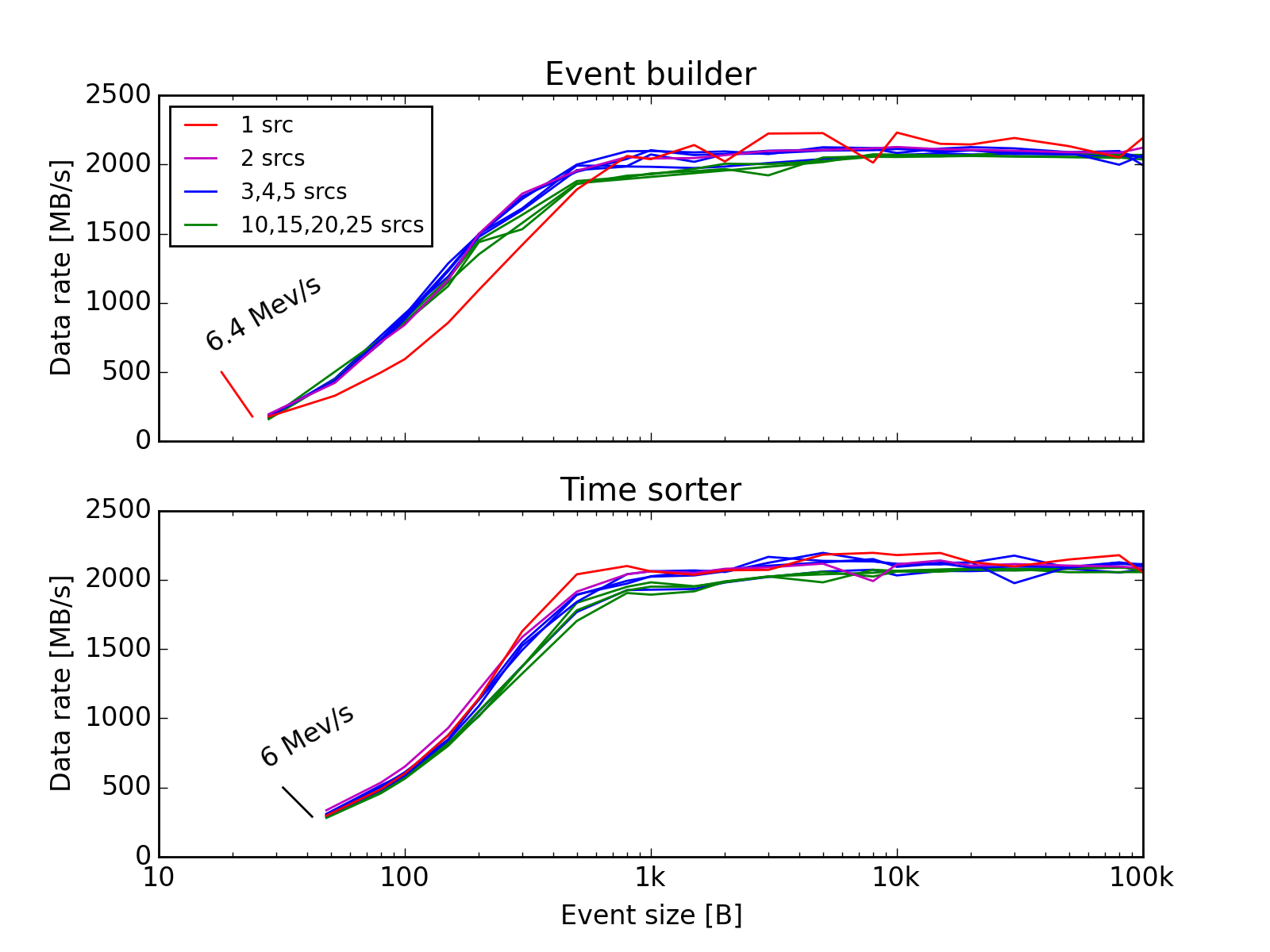
Merger performance, (upper panel) event builder and (lower panel) time sorter. Tested on one E3-1271v3 with 40 GbE connectivity from sources (readout), and to data destination. (In the event builder case, event sizes refers to the final events.)
Notes:
- With large event sizes, the copying of data dominates the throughput, here saturating at 2 GB/s.
- There are only very moderate scaling effects up to the 25 sources tested.
The saturation limit mainly applies to the actual merging / event building stage. Note that due to the large decoupling buffers between network input and actual merging, it is possible for a drasi merger node to momentarily accept much higher input volumes, e.g. during off-spill periods.
Clock cycle consumption¶
The CPU resources spent by the three worker threads involved in event building can also be expressed in clock cycles, per: fragment (part of event coming from each source), final event, and data size (bytes).
Note that the measurements giving the numbers below have been performed at approximately half the data and event rate the machine is capable of, in order to reliably disentangle the cost per event and data size. At saturation the numbers are higher (likely due to actual competition for memory latency and bandwidth); i.e. if using these numbers, the attainable rates would be overestimated. The numbers are still useful, e.g. to determine which task is the bottleneck.
| Task(thread) | clk/frag | clk/event | clk/B |
|---|---|---|---|
| Input (net) | 20 | 1.1 | |
| Merger, EB | 205 | 175 | 0.9 |
| Output (net) | 38 | 0.9 |
- The overhead of pure data copy is approximately the same for each of the tasks. The current limit is the network input thread. (This could with some reasonably small coding effort be made to use multiple threads and thus allow even higher momentary rates.)
- The overhead per event is largest for the merging thread. Still this is no limit in practice, since in the above measurement, 6.4 million fragments/s were handled.
The situation is very similar with the merger performing time-sorting:
| Task(thread) | clk/src | clk/event | clk/B |
|---|---|---|---|
| Input (net) | 20 | 1.1 | |
| Merger, TS | 33 | 340 | 0.9 |
| Output (net) | 38 | 0.9 |
In this case, there are no fragments — output events are as large as the input events. It is thus reasonable that the merger thread event overhead is close to the sum of the overhead for one fragment and one final event in event-building mode.