- Dynamic memory migration
- Replication of read-only memory
- Scheduling processes so that there is a lot of nearby memory
- Process scheduler knows memory affinity of processes
- Application writers may give placement hints
- Selectable and customizable policy choice
The operating system supports management of memory locality through a set of low-level system calls. These will not be of interest to the general user as the capabilities required to fine-tune performance have been made available in a high-level tool, dplace(1), and through compiler directives. But there are a couple of concepts which the system calls rely on which we will describe since terminology derived from them is used by the high-level tools. These are Memory Locality Domains (MLDs) and Policy Modules (PMs).
Every user of an Origin system will implicitly make use of MLDs and policy modules since the operating system uses them to maximize memory locality. This is completely transparent to the user and one does not need to understand these concepts to use an Origin system. But for those of you interested in fine-tuning application performance --- particularly of large, parallel jobs --- it can be quite useful to know not only that policy modules exist, but which types of policies are supported, and what those policies do, so please read on.
2.2.2 Memory Locality Domains (MLDs)
To understand the issues involved in memory locality management, a simple example is in order. Consider the scenario presented in the following diagram:
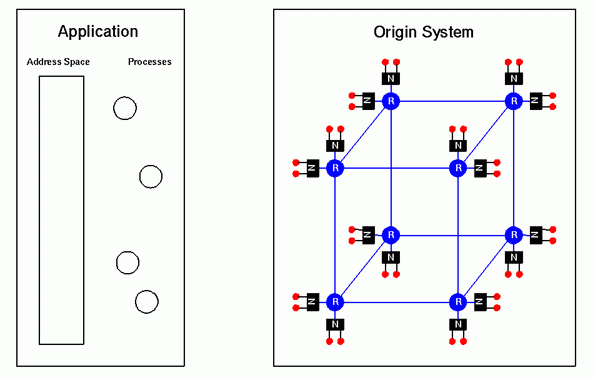
Here, we have a shared memory application using 4 processors which we want to run on an Origin system. This particular application exhibits a relatively simple memory access pattern. Namely, 90% of each process's cache misses are from memory accesses to an almost unshared section of memory, 5% to a section of memory shared with another process, and the remaining 5% to a section of memory shared with a third process. This is diagrammed below:

If we paid little attention to memory locality, we could easily end up with the situation shown below: a couple of processes end up running in one corner of the machine and the other processes end up running in an opposite corner. This results in the second and third processes incurring longer than optimal memory latencies to their shared section of memory.
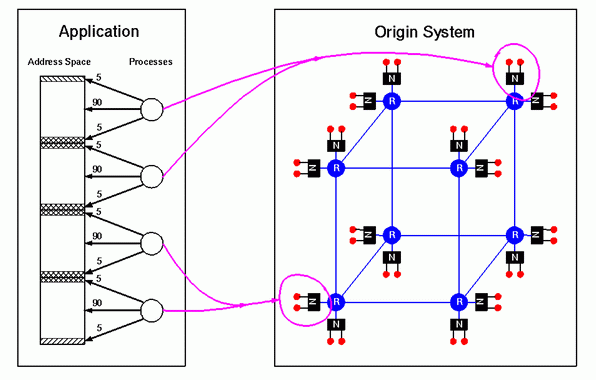
As it turns out, this situation is not so bad. Since the Origin hardware has been designed to keep the variation in memory latencies relatively small, and since accesses to the shared section of memory only accounts for 5% of the two processes's cache misses, the non-optimal placement will have a tiny effect on the peformance of the program.
But there are situations in which performance could be significantly impacted. If absolutely no attention were paid to memory locality, the processes and memory could end up as shown below:
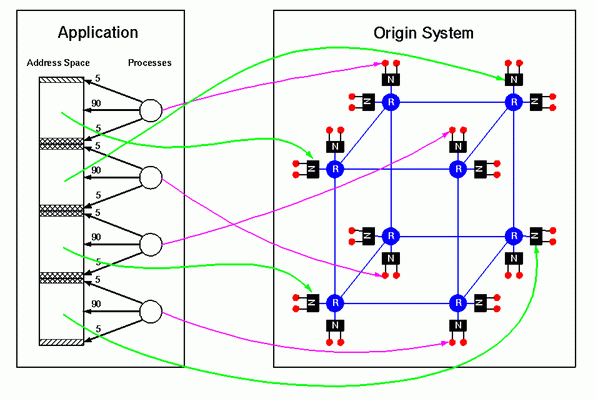
Here, each process runs on a different and distant node, and the sections of memory they use have been allocated from yet a different set of distant nodes. In this case, even the accesses to unshared sections of memory --- which account for 90% of each process's cache misses --- are non-local. Thus, the costs of accessing memory will increase. In addition, program performance can vary from run to run depending on how close each process ends up to its most-accessed memory.
The memory locality management mechanisms in Cellular IRIX are used to avoid such situations. Ideally, we would like the processes and memory used by this application to be placed in the machine as follows:
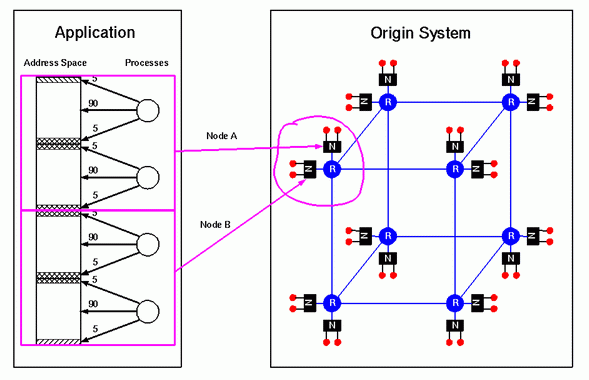
- The first two processes run on the two CPUs in one node,
- The other two processes run on the adjacent node's CPUs,
- The memory for the first pair of processes is allocated from the first node,
- The memory for the second pair of processes is allocated from the second node.
To allow IRIX to achieve this ideal placement, two abstractions of physical memory nodes are used:
- Memory Locality Domains (MLDs), and
- Memory Locality Domain Sets (MLDSETs).
A Memory Locality Domain is a source of physical memory. It can be one node, if there is sufficient memory available for the process(es) which will run there, or several nodes within a given radius of a center node. For the example application, the OS will create two MLDs, one for each pair of processes:
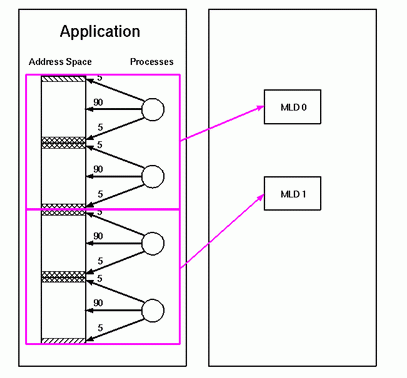
It will be up to the operating system to decide where in the machine these two MLDs should be placed. Since optimal performance requires that they be placed on adjacent nodes, the operating system needs some additional information is required. This brings us to MLDSETs.
Memory Locality Domain Sets describe how a program's MLDs should be placed within the machine and whether they need to be located near any particular hardware devices (e.g., graphics). The first property is known as the topology, and the second is resource affinity. Several topology choices are available. The default is to let the operating system place the MLDs on a cluster of physical nodes which is as compact as possible. Other topologies allow MLDs to be placed in hypercube configurations (which are proper subsets of Origin's interconnection topology) and on specific physical nodes. The diagram below shows the MLDs for the example application placed in a one-dimensional hypercube topology with resource affinity for a graphics device:
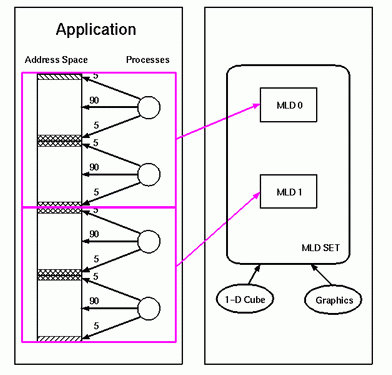
2.2.3 Policy Modules (PM)
With the MLDs and MLD set defined, the operating system is almost ready to to attach the program's processes to the MLDs, but one thing more remains to be done: policy modules need to be created for the MLDs. Policy modules tell the operating system the following:
- How pages of memory should be place in the MLDs
- What page size should be used
- What fallback policies to use if the resource limitations prevent the preferred placement and page size choices from being carried out
- Whether page migration is enabled
- Whether replication of read-only text is enabled
The operating system will use a set of default policies unless instructed to do otherwise. The user may change the defaults through the utility dplace(1) or via compiler directives. Once the desired policies have been chosen, the operating system then maps processes to MLDs, as shown below:
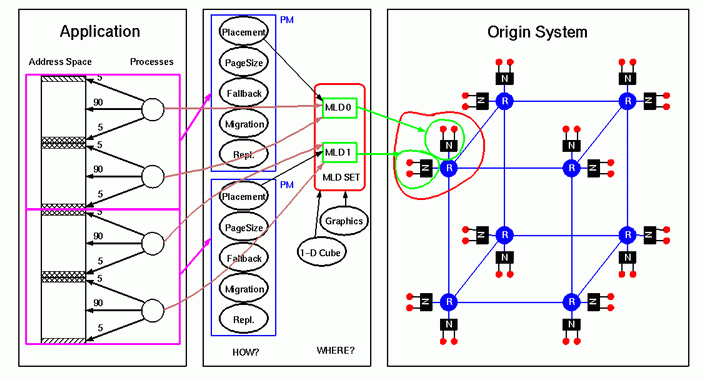
This ensures that the application threads execute on the nodes from which the memory will be allocated.
Data Placement Policies
While it may be obvious to the application writer what the memory access patterns for the application are --- and hence which MLD each section of memory should be allocated from --- there is no way for the operating system to know this. The placement policies determine how data are allocated from the different MLDs in the MLD set.
Three memory placement policies are available:
- First touch, in which the memory holding a data structure is allocated from the MLD whose associated process has first accessed the data structure,
- Fixed, in which the data structure is allocated from a specific MLD, and
- Round-Robin, in which the pages of memory comprising a data structure are allocated in a round-robin fashion from the MLDs in the MLD Set.
The default policy is first touch. If neither dplace nor compiler placement directives have been used, this policy will dictate how data structures are allocated from the available MLDs. Under this policy, the first processor to touch a data element will cause the page of memory holding the data element to live in the memory of the node on which the process is running. This memory placement policy will work well for programs which have been parallelized completely from beginning to end. Returning to the example program above, if the initialization of the data structures is done in parallel, each processor will be the first to touch the 90% of "its" data that it wishes to reside in its local memory, causing those data to be allocated locally. The remaining 5% pieces will end up stored in the memory of one or the other of the two processors which access each piece. (While there is no absolute guarantee that this is exactly the desired layout, from a performance point of view, it should be equivalent.)
As a programmer, you can use the first touch policy to your advantage. By parallelizing the program so that data are initialized by the processor whose memory you would like the data to reside in, you can guarantee a good placement of the data. While this is an extra consideration not required in a bus-based system such as Power Challenge, it is generally very simple to do and does not require you to learn anything new, such as the compiler directives which also allow data to be placed optimally.
If a program has not been completely parallelized, the first touch policy may not be the best one to use. For our example application, if all the data are initialized by just one of the four processes, all the data will be allocated from a single MLD, rather than being evenly spread out among the 4 MLDs. This introduces two problems:
- Accesses which should be local are now remote.
- All the processes will have their cache misses satisfied from the same memory. This may cause a performance bottleneck.
What can one do to remedy this?
If migration is enabled, the data will eventually move to where they are most often accessed, so ultimately they should be placed correctly. This works well for applications in which there is one optimal data placement and the application runs long enough for the data to be migrated into their optimal locations.
But in more complicated applications, in which different placements of data are needed in different phases of the program, there may not be enough time for the operating system to move the data to where they need to be for a particular phase before that phase has finished and a new one has begun. For such applications, a round-robin placement policy may be best. Under this policy, the data are evenly distributed among the MLDs. They are not likely to be in an optimal location at any particular point in the program, but by spreading the data out, we avoid creating performance bottlenecks.
This is actually a more important consideration than getting the data to the place where the latency is the lowest. The variation in memory latency is not that great in Origin systems, but if all the data are stored in one the memory of one node, dozens of processors will not be able to access different pieces of the data with anywhere near the bandwidth they could achieve if the data were evenly spread out among the processing nodes.
The final placement policy is fixed placement. This places pages of memory in a specific MLD. This is accomplished by using the compiler placement directives. These are a convenient way to specify the optimal placement of data. And since one can use different placements in different parts of a program, they are ideal for more complicated apploications in which multiple data placements are required.
The initial placement of data is an important factor for consistently achieving high performance on multi-processor applications. It is not an issue for single processor applications since there is only one MLD from which to allocate memory. There is, however, one difference you may see in running on an Origin compared to a bus-based system. Applications with modest memory requirements are likely to succeed in allocating all their memory from the node on which they run. In such cases, all cache misses will see local memory latencies. But as an application's data requirements grow, it may need to draw memory resources from nearby nodes. As a result, some cache misses will have longer latencies. Thus, the effective time for a cache miss can increase as the size of the data an application uses grows, or if other jobs consume more of the memory on the node.
2.3 Recommendations for Achieving Good Performance
The memory locality management automatically performed by IRIX means that most Origin users will be able to achieve good performance and enhanced scalability without having to program any differently than they do an a Power Challenge. But Origin does employ a NUMA architecture, and this will affect the performance of some programs which were developed on a uniform memory access achitecture. In this section we summarize when you can expect to see artifacts of the NUMA architecture, and what tools you can use to minimize them.
Even though Origin is a highly parallel system, the vast majority of programs run on it will use only a single processor. Nothing new or different needs to be done to achieve good performance on such applications: tune these just as you would a single processor program that is to be run on a Power Challenge. Section 3, Single Processor Tuning, provides a detailed discussion of the tools available and steps you can take to improve the performance of uniprocessor programs.
There is one new capability in the Origin system, though, which single processor programs can sometimes take advantage of to improve performance, namely, support for multiple page sizes. Recall that the page size is one of the policies that IRIX 6.4 uses in allocating memory for proceses. Normally, the default page size of 16 KB is used, but for programs which incur a performance penalty due to a large number of TLB misses, using a larger page size can be advantageous. For single processor programs, page size is controlled via dplace(1). This is explained in the single processor tuning section.
Single processor tuning will account for most of the performance work you do on Origin. Don't scrimp here: the use of the proper compiler flags and coding practices can yield big improvements in program performance. Once you have made your best effort at single processor tuning, you can turn your attention to issues related to parallel programming. We separate parallel programs into two classes:
- MP-library programs: These use the shared memory parallel programming directives which have been available on SGI systems for many years.
- Non-MP library programs: These include MPI, PVM, and other threaded programs.
For parallel programs which do not use the SGI MP directives, it is a good idea to make use of the dplace(1) utility. This is especially true for programs linked with the 2.0 release of MPI. This version of MPI was developed on Power Challenge. As a result, no attention was paid to making sure data structures used in the library are distributed among the MPI processes which comprise the program. This can sometime result in less than ideal scaling since some of these data structures may create bottlenecks. Use of dplace(1) can help in distributing these data, and this will improve scalability. Use of dplace on MPI jobs is described in section 4.5.1. Note, though, that the 3.0 release of the MPI library will be updated for Origin, and so once it has been released, there should be no need to use dplace for MPI jobs, unless you want to change a policy such as page size.
The second class of parallel programs are those that use the MP-library. Programs in this class which make good use of the R10000's caches will see little effect from Origin's NUMA architecture. The reason for this is that memory performance is only affected by memory latencies if the program spends a noticeable amount of time actually accessing memory, as opposed to cache. But cache-friendly programs have very few cache misses, so the vast majority of their data accesses are satisfied by the caches, not memory. Thus, the only NUMA effect cache-friendly parallel programs will see on Origin is scalability to a larger number of processors. The perfex(1) and SpeedShop tools can be used to determine if a program is cache-friendly; their use should be an integral part of your tuning efforts. You can find a detailed discussion of their use in the single processor tuning section.
Not all programs can be made cache-friendly, however. That's alright, it just means they will spend more time accessing memory than their cache-friendly brethren, and in general will run at lower performance. This is just one of the facts of life for cache-based systems, which is to say, all computer systems except very expensive vector processors.
In comparing the performance of non-cache-friendly parallel programs on Origin vs. Power Challenge, you are likely to see a marked improvement in performance on Origin since its access times to local memory are significantly faster than Power Challenge. If you observe better performance and scalability, then the operating system has succeeded in placing the data so that the majority of the memory accesses local, and there is nothing more you need to do.
On the other hand, if there is a performance or scalability problem, the
data have not been optimally placed, and modifing the placement policies
can fix this. The first thing to do is try is a round-robin placement policy.
For programs which have been parallelized using the SGI MP directives, round-robin
placement should be enabled using the _DSM_ROUND_ROBIN environment variable (see section 4.5.4 for details). If this solves the
performance problem, you're done. If not, try enabling migration with the _DSM_MIGRATION environment variable (see section 4.5.5 for details). In addition, you
can try both round-robin placement (which just affects initial data layout)
and migration (which will continually update the data layout as the program
runs) together.
Often, these policy changes will be all that is needed to fix a performance problem. They are very convenient since they require no modifications to your program. In some instances, though, they will not be sufficient to fix a performance or scalability problem. In these cases, you will need to modify the program to ensure that the dat are optimally placed. This can be done in a couple of ways. You can make use of the default first touch policy and program so that the data are first accessed by the processor in whose memory they should reside. This is easy to do and does not require learning any new compiler directives. The second way to ensure proper data layout is to use the data placement directives. These permit you to locate data in exactly the way that is optimal for your program. In addition, they also allow you to redistribute the data as the program runs so that they are always optimally placed. The use of these directives is described in section 4.5.6.